
Abstract
Large Language Models (LLMs) :
- Encounter challenges such as :
- Hallucination
- Outdated knowledge
- Non-transparent, untraceable reasoning processes.
Solution :
Retrieval-Augmented Generation (RAG) : Incorporating knowledge from external databases.
II. OVERVIEW OF RAG

Typical Application of RAG
- A common scenario is illustrated where RAG is used to answer a user's query by retrieving relevant document chunks from external databases.
- This approach bridges the gap when LLMs lack the capacity to provide up-to-date or domain-specific information.
Components of RAG
- Indexing:
- Cleaning and extraction
- raw data (in diverse formats like PDF, HTML, Word, and Markdown) → uniform plain text → chunks → (encode using an embedding model) → vector representations
- This step is crucial for enabling efficient similarity searches in the subsequent retrieval phase
- Retrieval:
- Transforms user queries into vector representations.
- Computes similarity scores between query vectors and document vectors to retrieve relevant chunks.
- Generation:
- Synthesizes retrieved documents and user queries into coherent prompts.
- LLMs use these prompts to generate responses, drawing on both intrinsic and retrieved knowledge.
Naive RAG
- Introduction
- Represents the earliest methodology.
- Follows a traditional process of indexing, retrieval, and generation.
- Characterized as a "Retrieve-Read" framework.
- Challenges and Limitations
- Retrieval Challenges : Faces issues with precision and recall during retrieval.
- Generation Difficulties : Generation phase can suffer from hallucinations and irrelevance.( irrelevance, toxicity, or bias)
- Augmentation hurdles :
- Integrating retrieved information with the different task → Include disjointed or incoherent outputs.
- Similar information is retrieved from multiple sources → redundant outputs and difficulty integrating retrieved information.
- various passages and ensuring stylistic and tonal consistency → complexity
- Facing complex issues, a single retrieval based on the original query may not suffice to acquire adequate context information
Advanced RAG
- Introduction
- Introduces improvements to overcome the limitations of Naive RAG.
- Focuses on enhancing retrieval quality using pre-retrieval and post-retrieval strategies.
- Optimizes indexing and retrieval processes for better performance.
Modular RAG
- Introduction
- Advances beyond Naive and Advanced RAG, offering greater adaptability and versatility.
- Incorporates diverse strategies for improving retrieval and processing.
- Supports sequential processing and integrated end-to-end training across components.
Challenges and Limitations
- Naive RAG:
- Advanced and Modular RAG:
- Address these limitations with refined indexing techniques, enhanced retrieval methods, and flexible module configurations.
Comparison of RAG Paradigms
- Naive RAG:
- Simple, sequential process with basic indexing, retrieval, and generation.
- Advanced RAG:
- Incorporates optimization strategies around pre-retrieval and post-retrieval processes.
- Still follows a chain-like structure.
- Modular RAG:
- Greater flexibility with multiple specific functional modules.
- Supports iterative and adaptive retrieval methods, not limited to sequential processing.
Illustrative Examples
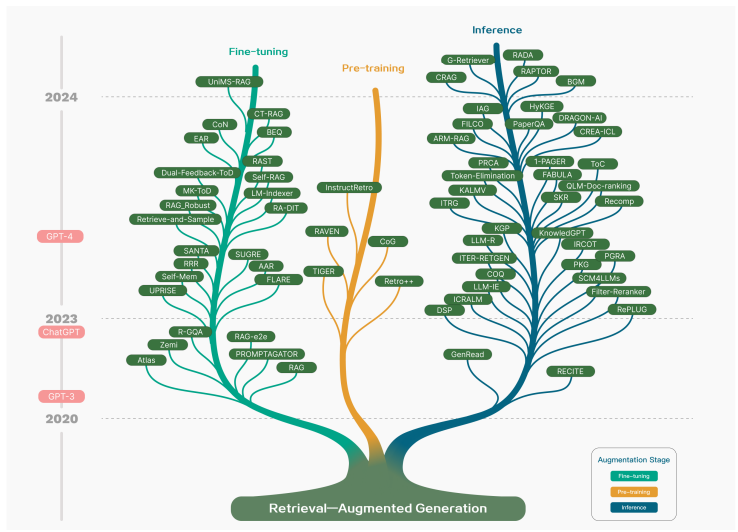
- Figures in the paper illustrate the technology tree of RAG research and comparisons between the three paradigms of RAG.
- Examples show how RAG can be applied to enhance the accuracy and relevance of LLM-generated answers.
'LLM' 카테고리의 다른 글
| LangChain이란? (0) | 2024.08.02 |
|---|---|
| LangChain으로 ChatGPT API 활용하기 (0) | 2024.07.31 |
| RAG (Retrieval-Augmented Generation) 관련 논문 (1) | 2024.07.24 |
| [LLM] Transformer Architecture (1) | 2024.05.24 |
| [LLM] LLM에서 Retriever란? (1) | 2024.04.19 |